Künstliche Intelligenz
Wie können Maschinen lernen? Die Grundlagen für diese Technologie liegen in der Mathematik. An dieser Station können Sie einige grundlegende Prinzipien ausprobieren. Scrollen Sie nach unten, um alle verfügbaren Audiokommentare zu sehen.Gradientenverfahren
Text lesen ...
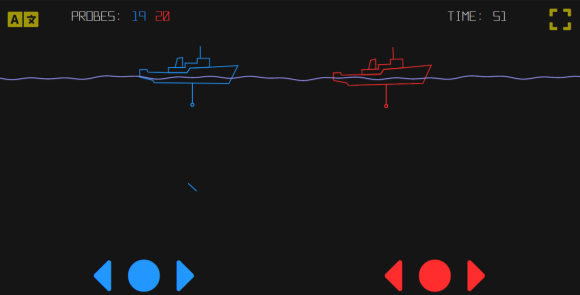
Am tiefsten Punkt des Meeresbodens ist ein Schatz versteckt. Das Ziel des Spiels ist es, diesen Schatz zu finden. Nutzen Sie die Pfeiltasten, um ihr Schiff zu bewegen und drücken Sie den runden Knopf, um eine Sonde auf den Meeresgrund zu schicken. Was ist Ihre Strategie, um den Schatz möglichst schnell zu finden?
Die beste Methode ist es, das Gefälle zu beachten. Wie steil ist es an den untersuchten Stellen und in welche Richtung neigt sich der Boden? Eine kluge Strategie ist, den steilsten Abhang weiter hinunterzugehen.
Genauso lernt eine künstliche Intelligenz. Sie sucht nach einem tiefsten Punkt, nämlich dem tiefsten Punkt einer Fehlerfunktion. An diesem Punkt ist der Fehler ihrer Berechnungen am kleinsten. Der mathematische Algorithmus dahinter nennt sich Gradientenverfahren. Zuerst erhält eine KI Beispiel-Eingaben, aus denen sie ein Ergebnis berechnet. Man vergleicht dieses Ergebnis mit dem echten Ergebnis und meldet der KI zurück, wie groß der Fehler ist. Die KI versucht dann ihre Berechnung so anzupassen, dass der Fehler kleiner wird. Sie berücksichtigt dabei den Gradienten, also die Steigung der Fehlerfunktion. In welcher Richtung wird der Fehler kleiner?
Wenn die KI genügend trainiert wird, kann sie ihre Berechnungskoeffizienten so anpassen, dass der Fehler minimal ist. In der Praxis geschieht das meist mit Millionen von Beispieldatensätzen.
Es kann allerdings passieren, dass die KI in einem „lokalen Minimum“ stecken bleibt und das „absolute Minimum“ nicht findet. Das ist wie bei der Schatzsuche. Sie können an einem tiefen Punkt landen, der von Bergen umgeben ist. Doch der tiefste Punkt des gesamten Geländes befindet sich an einer anderen Stelle. Um dieses Problem zu lösen, kombiniert man das systematische Gradientenverfahren mit einer Prise Zufall und startet die Suche einfach an einem zufälligen Punkt neu.
Neuronale Zahlen
Text lesen ...
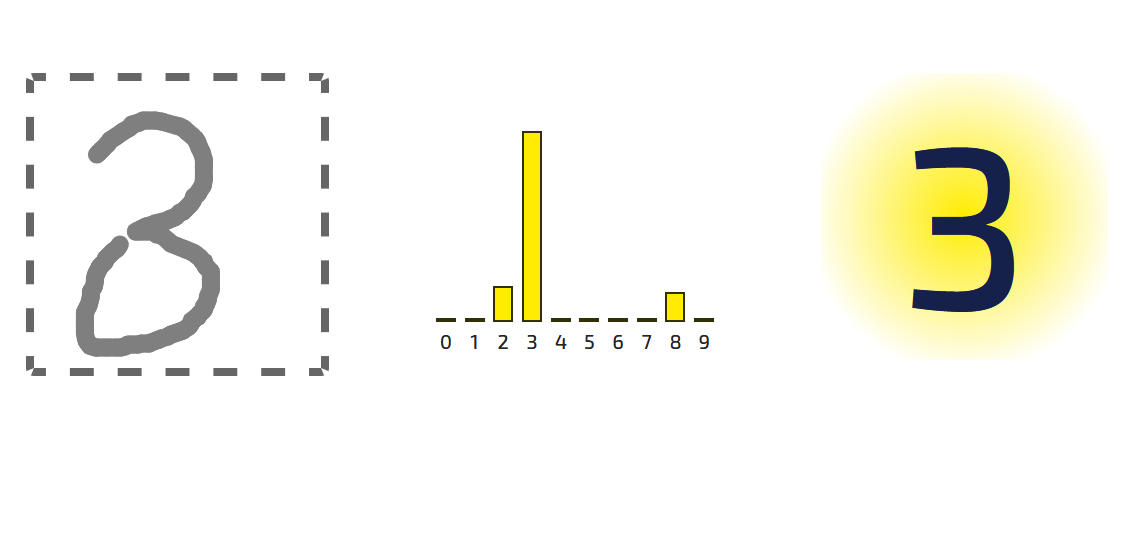
Formen und Muster korrekt zu erkennen, ist eine häufige Aufgabe für künstliche Intelligenzen. In diesem Beispiel geht es um handgeschriebene Ziffern.
Handschriften sind eine Herausforderung, weil sie von Natur aus unregelmäßig sind. Selbst eine einzelne Person schreibt dieselbe Zahl nicht immer gleich. Eine kleine Änderung kann ausreichen, um aus einer Eins eine Sieben zu machen oder aus einer Drei eine Acht.
Schreiben Sie eine Zahl zwischen Null und Neun mit dem Finger auf den Bildschirm. Ein künstliches neuronales Netz erkennt in Echtzeit, welche Ziffer gemeint ist. Welche Ziffer erkennt der Computer am besten? Bei welchen Ziffern hat er Probleme? Probieren Sie aus, was geschieht wenn Sie das neuronale Netz trainieren oder wenn Sie die Eigenschaften des neuronalen Netzes verändern.
Ein künstliches neuronales Netz ist ein Algorithmus, der das Verhalten von vielen, vernetzten Neuronen nachahmt. Jedes künstliche Neuron nimmt Informationen auf, verarbeitet sie und leitet sie gegebenenfalls weiter. Unser Beispiel arbeitet mit 100 künstlichen Neuronen. Sie erhalten die Helligkeitswerte des Bildes als Eingabewerte. Das sind in unserem Beispiel 784 Werte. Jedes Neuron erhält eine bestimmte Anzahl der Eingabewerte. Es multipliziert die Eingabewerte mit sogenannten Gewichten, rechnet alles zusammen und addiert einen Bias hinzu. Dann verwendet das Neuron eine Aktivierungsfunktion, um zu entscheiden ob der Wert weitergegeben wird. Die Aktivierungsfunktion könnte zum Beispiel so eingestellt sein, dass positive Werte direkt weitergegeben werden, bei negativen Werten hingegen 0 ausgegeben wird.
Ein künstliches neuronales Netz lernt anhand von Beispielen. Es „weiß” am Anfang nichts. Durch Training mit sehr vielen Beispieldaten kann es die Gewichte und den Bias Schritt für Schritt anpassen und genauere Ergebnisse erzielen. In unserem Beispiel bestehen die Trainingsdaten aus sehr vielen handgeschriebenen Ziffern und der Information darüber welche Ziffer jeweils gemeint ist.
Sumory
Text lesen ...
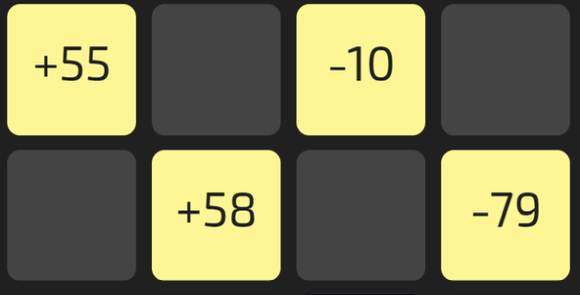
Hinter jedem hellgrauen Feld auf dem Bildschirm steckt eine positive oder negative Zahl. Klicken Sie die Felder an und versuchen Sie in 10 Zügen eine möglichst hohe Gesamtsumme zu erreichen. Die Felder können mehrfach angeklickt werden.
Welche Strategie führt zu einem guten Ergebnis? Sollten Sie möglichst viele verschiedene Felder ausprobieren oder ab einem bestimmten Wert immer auf dasselbe Feld setzen?
Mit dieser Frage beschäftigen sich auch die Entwickler von künstlichen Intelligenzen. Wenn eine künstliche Intelligenz in einer unbekannten Umgebung eine Lösung finden soll, muss Sie die Umgebung zunächst erkunden. Ab einem bestimmten Punkt wird sie jedoch ihr erworbenes Wissen nutzen, um zu einem Ergebnis zu kommen - bis sich die Situation ändert und sie wieder etwas Neues ausprobieren muss.
Es gibt verschiedene mathematische Algorithmen, die dabei helfen, die richtige Balance zwischen dem Erkunden und dem Ausnutzen zu finden. Spiele sind ein hervorragendes Forschungsfeld, um solche Algorithmen zu entwickeln und zu testen. Im Jahr 2016 ist es dem Computerprogramm Alpha-Go gelungen, einen der besten Go-Spieler der Welt zu besiegen. Die Entwickler von Alpha-Go verwendeten ein Monte Carlo Tree Search-Verfahren. Dabei handelt es sich um einen mathematischen Algorithmus der zwischen dem Erkunden und dem Ausnutzen besonders geschickt ausbalanciert.
Bestärkendes Lernen
Text lesen ...
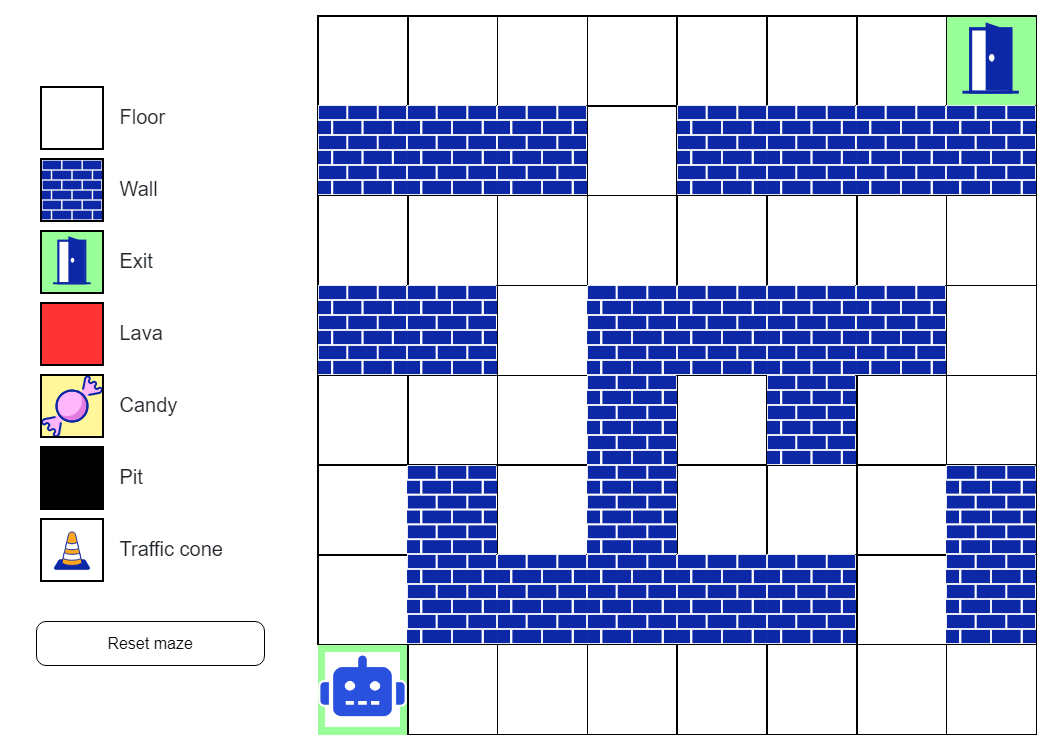
Gestalten Sie ein Labyrinth und lassen Sie den Roboter den Ausgang suchen. Setzen Sie Hindernisse ein, um es schwieriger zu machen. Verwenden Sie Belohnungen, um den Roboter in einem bestimmten Verhalten zu bestärken. Beobachten Sie, wie der Roboter lernt. Wie wichtig ist das Erkunden im Vergleich zum Wiederholen von bekannten Handlungen?
Reinforcement Learning oder auch „Bestärkendes Lernen“ bezeichnet eine Reihe von Methoden, bei denen eine künstliche Intelligenz durch Versuch und Irrtum lernt. Die Grundidee ist, dass das Programm versucht, positive Rückmeldungen oder Belohnungen zu maximieren.
Im Gegensatz zum Lernen mit Trainingsdaten erhält die künstliche Intelligenz hier keine Beispiele für richtiges oder falsches Verhalten. Sie muss dieses Wissen selbständig durch Interaktion mit ihrer Umgebung erarbeiten. Damit ahmt das Reinforcement Learning eine Form des menschlichen Lernens nach, das in der Lernpsychologie als Konditionierung bekannt ist. Richtiges Verhalten wird durch Belohnung verstärkt. Falsches Verhalten wird durch Bestrafung abgeschwächt.
Dabei tritt jedoch ein Dilemma auf. Wie häufig sollen neue Handlungen ausprobiert werden? Wie lange sollen erfolgreiche Aktionen wiederholt werden? Die Entwicklung von leistungsfähigen Algorithmen zur Lösung dieses Dilemmas ist ein aktives Forschungsfeld.